Improving S3 performance from C++
How do we maximise S3 random IOPS throughput at different block sizes and queue depths?


At Yellowbrick, we've been working to support storing primary database data on external storage systems, including those speaking S3 and NFS protocols. My colleagues Santhosh and Yang recently spent quite some time analysing and tuning the performance of the S3 object store.
In cloud architecture, local storage is ephemeral, so the only way to reliably persist data is by writing it to some form of remote storage, and S3 object storage is the most cost effective. It's got terrible latency, though, so to maximise bandwidth and IOPS, large IO queue depths across many targets have to be built up. We use blocks of the order of 256KB (substantially larger than the block size used for local persistent storage and cache) which appears to be a good trade-off between read IOPS and throughput.
We've been very disappointed with the state of networking on AWS because their claims tend to be rather inflated: Their maximum rates per second conspicuously emit details and steps to reproduce, and their RDMA story is nowhere near as complete or efficient as they would have you believe. We ran into the same disappointment working with AWS's C++ SDK too.
AWS SDK issues
We are driving S3 from C++, and one of the first factors we hit was the quality of Amazon's own client library. While flexible and capable, it's very inefficient code based on libcurl. The rule still generally holds that, if you need something to run optimally, you have to write it yourself. Upon profiling with perf, we find the top of the list is gratuitous excess data copying, followed by a great deal of layering, more copying, inefficient parsing, all performed with expensive ephemeral allocations. We also started getting network errors beyond 256 'clients.'
AWS's asynchronous GET implementation is hopelessly inefficient. A profile running with large queue depths is shown here:
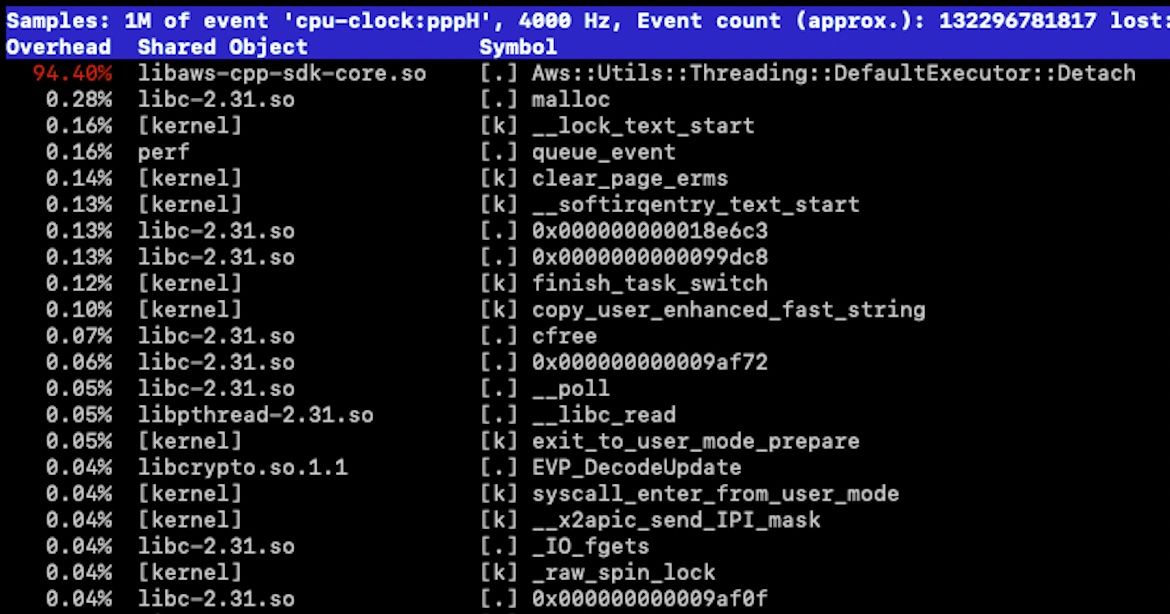
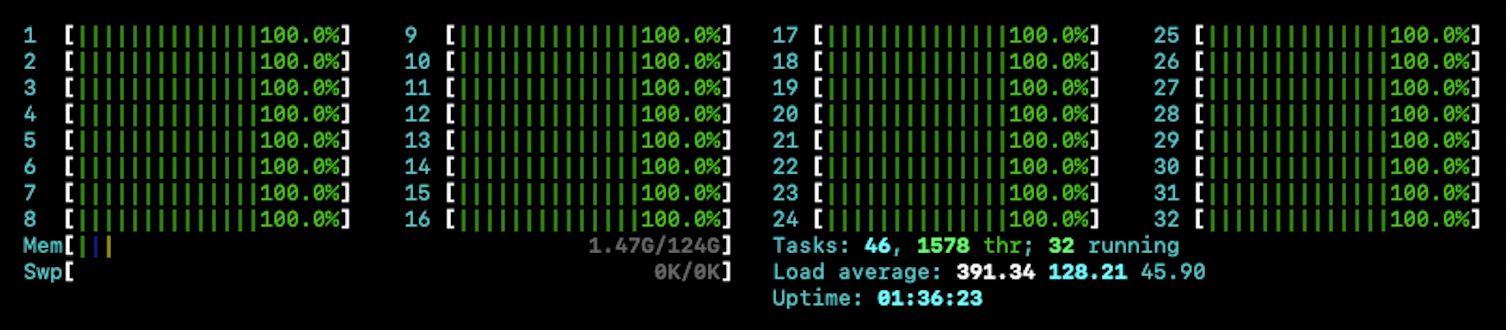
The library's default executor spawns large numbers of threads unnecessarily, and detaching such things used 100% of a 32-core machine. Using a pooled executor helped things substantially, using only 40% of said machine, but still 10x slower than our own implementation. Using AWS's synchronous GET request, creating threads on the outside, helped things substantially, however... Come on Amazon - asynchronous APIs are supposed to be more efficient than synchronous ones!
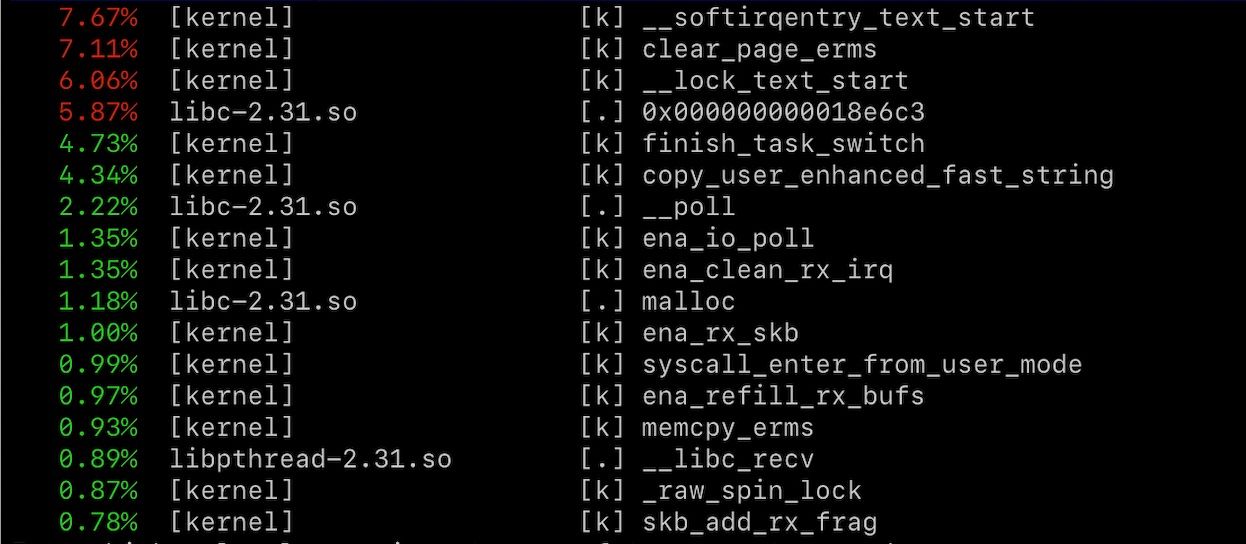
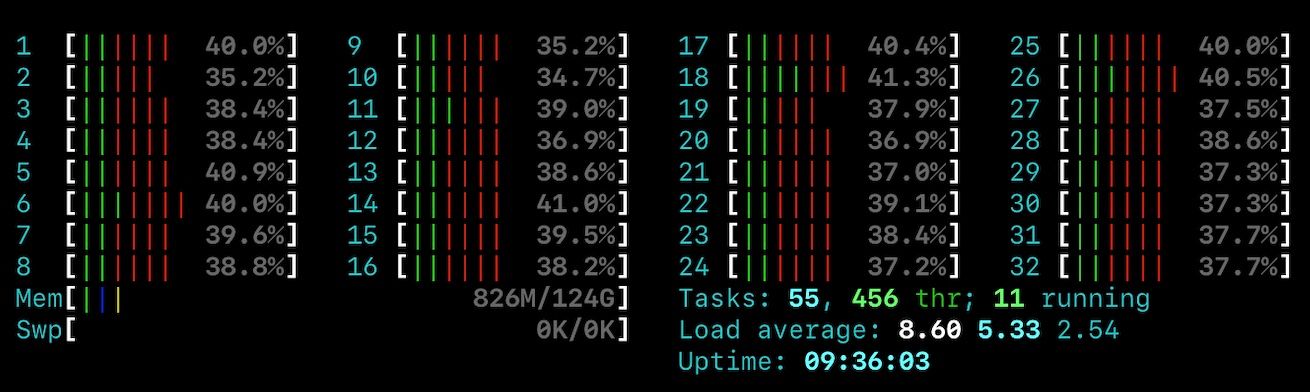
Creating boat loads of threads to achieve high queue depths needed to saturate the network bandwidth on S3 is still a poor bit of software architecture, and not really practical given the large number of sockets we need to open to work around S3's high latency.
Although the CPU usage has dropped a lot, the overall bandwidth achieved from the synchronous implementation was still only 1/3 of our own library. By developing our own access library, we can vertically integrate something more efficient, avoid data copying and allocate and recycle pre-sized buffers. We can tightly control how many sockets we use and how we pipeline HTTP/HTTPS requests on these sockets without excessive CPUs or threads. We can adaptively parse streams without unnecessary data copies and optimise for NUMA multi-core configurations where needed.
Our own stack reduces user space CPU consumption to a level that is barely visible, although Linux's kernel still uses around 6-8 vCPU when saturating the network on an m5n.8xlarge instance (32 vCPUs with 25Gb/sec network throughput). What's going on with the Linux kernel?
Linux issues
Our friend the Linux kernel is still holding us back, especially on larger instances. Unfortunately doesn't appear to be a great deal that can be done about this. Looking at perf-top on an worst-case kind of hardware instance, the huge i3en.metal with 64 threads and 1024 sockets, running kernel 5.10, we see:
| % | Area | Function |
|--------|----------|-----------------------------------------|
| 29.24% | [kernel] | copy_user_enhanced_fast_string |
| 20.04% | [kernel] | native_queued_spin_lock_slowpath.part.0 |
| 3.50% | [kernel] | __check_object_size.part.0 |
| 2.90% | [kernel] | skb_release_data |
| 2.79% | [kernel] | __list_del_entry_valid |
| 1.53% | [kernel] | __skb_datagram_iter |
| 1.35% | [kernel] | __free_one_page |Much of the time is spent contending on a spin lock. Originally, we started with kernel version 4.14, where the spin lock accounted for almost 90% of the CPU!
It is likely that this will improve in future versions of the kernel; for now, we are content that we can maximise S3 bandwidth without consuming all of the CPU, especially on the smaller instances that are commonly deployed. For actual data exchange when running queries, we have developed our own UDP-based protocol that bypasses the Linux kernel entirely, using Intel's DPDK, to fully maximise bandwidth while consuming little overall CPU. If we have instances with even faster networking to S3 in future, we may need to also use some sort of kernel bypass methodology to connect to S3 to avoid consuming too much CPU.
Results and conclusion
Overall we are pretty happy with how well things have come together. For various instance types, we see this read performance from S3 with a 256KB block size:

This is very respectable; we are able to use the vast majority of the available network bandwidth—much of the variability is due to AWS's own infrastructure—without burning through a hideous amount of CPU. Such results are impossible with Amazon's own SDK.
If we were to do user space TCP, we could maximise S3 bandwidth using almost no CPU. It would be wonderful if Amazon make such a library in future, however it would probably be an economic disincentive for them to do so: Less CPU consumption results in less revenue for most workloads. Cloud providers really don't have a good incentive to make more efficient software once it's "good enough" to migrate or run new workloads—and this definitely falls into the category of "good enough."
Many thanks to Santhosh and Yang for sharing the results of their work.